LLM App / Agent / Full-stack
2026
角色: 产品定义、工作流设计、交互定义、全栈 MVP 实现
CareerPilot
一个将零散求职任务整合为单一工作流的 AI 求职工作台,覆盖 JD 分析、经历证据匹配、简历改写、面试准备与可追踪生成。
影响: 将我自己的求职痛点转化为可演示的 AI 产品,让申请流程更结构化、更可检查,也更容易规模化做个性化定制。
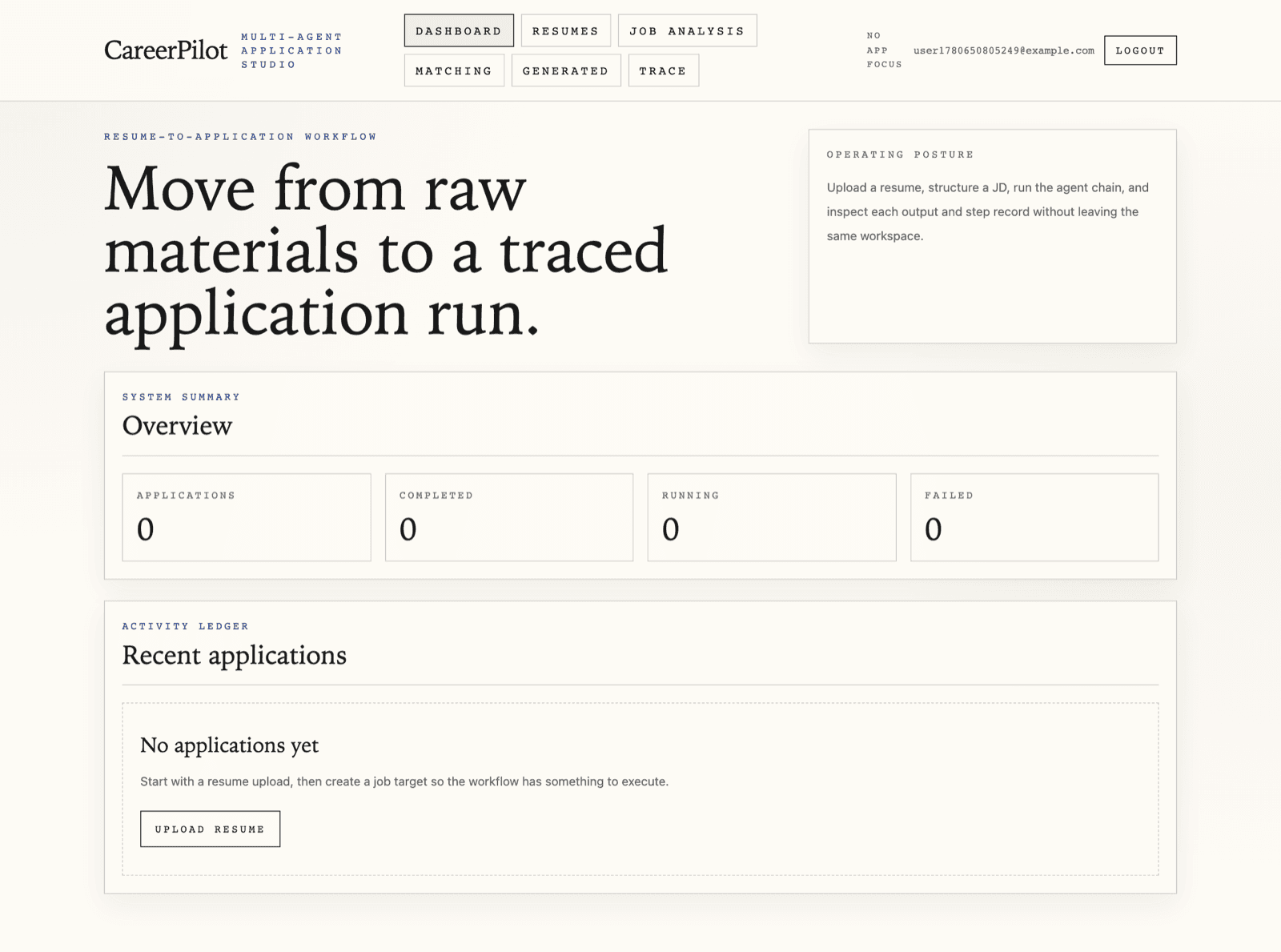

概览
CareerPilot 是一个围绕完整求职闭环设计的 AI 工作台:上传简历、理解 JD、匹配经历证据、生成定制化内容,并回看推理路径。我把它定义成工作流产品,而不是几个孤立提示词页面。
问题
学生和早期求职者往往需要同时申请多个岗位,但同一段经历在不同岗位中需要不同表达。真正困难的不只是把句子写得更好,而是找到合适证据、匹配岗位要求,并确保每一句生成内容都不夸大。
解决方案
我把体验拆成清晰的产品阶段:岗位要求提取、简历证据检索、匹配分析、简历改写、求职信生成和面试准备。这样拆分后,产品更容易建立信任、调试问题,也更适合面试场景下展示。
架构
项目采用 monorepo 架构,包括 FastAPI 后端、Celery worker、React 前端、共享 TypeScript contracts、Alembic 数据库迁移、基于 Docker 的本地编排、用于异步工作流的 Redis,以及面向向量存储的 Postgres + pgvector 设计。
核心功能
- 简历导入与结构化解析
- 岗位描述分析与能力要求提取
- 基于证据的简历-JD 匹配建议
- 定向简历改写与求职信生成
- 基于岗位匹配结果的面试准备
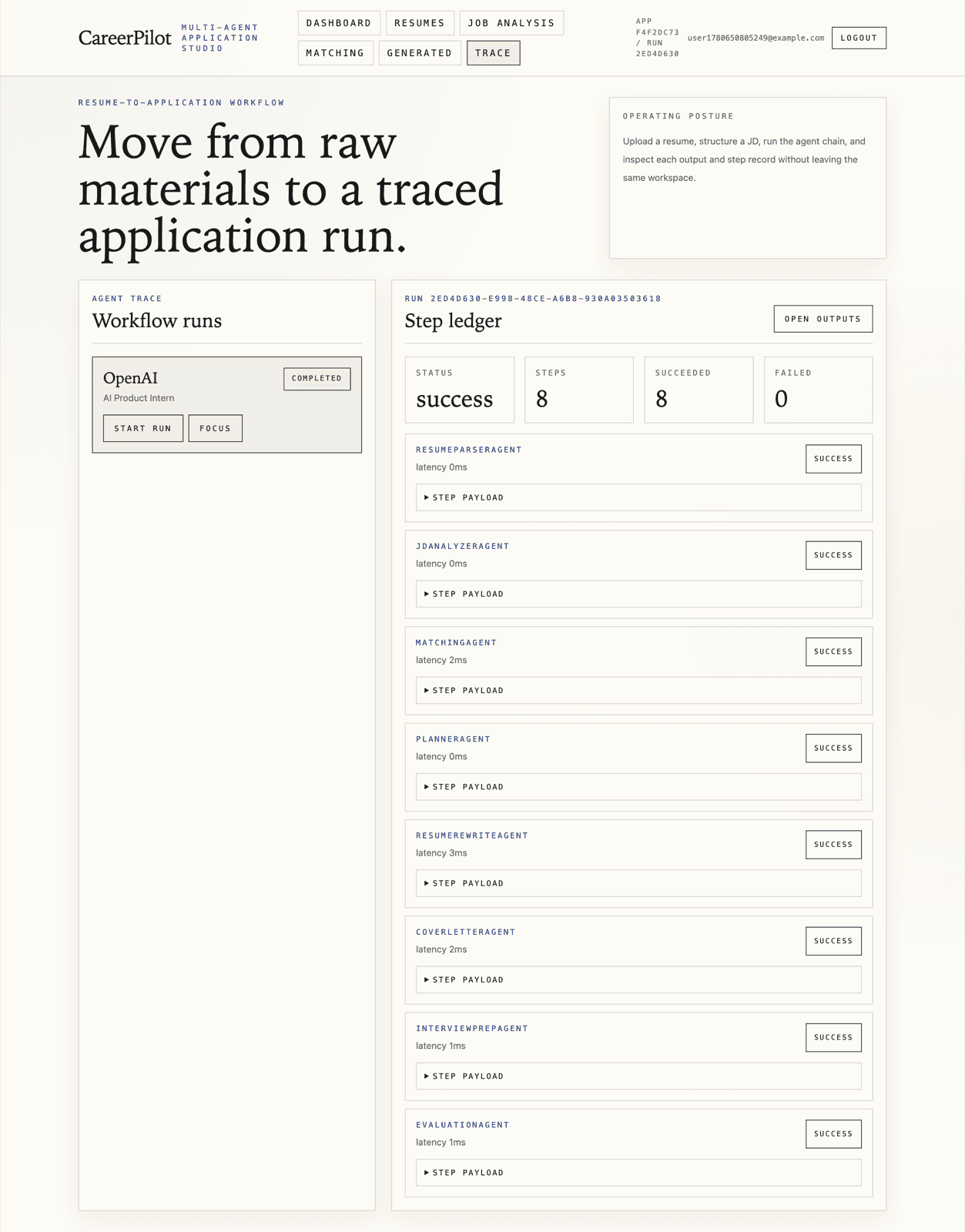
- 用于检查工作流输出的 Agent 轨迹观测
技术栈
- Python
- FastAPI
- React
- Celery
- PostgreSQL
实现细节
- 将项目设计为 monorepo,拆分为 API、worker、web、shared contracts 和 Docker infrastructure 等模块。
- 通过 Celery 和 Redis 实现异步生成,使耗时的 LLM 调用不会阻塞普通请求响应链路。
- 设计基于环境变量的模型 provider 配置:可以启用 DeepSeek 实时生成,也可以在测试和 demo 中回退到确定性本地生成。
- 加入后端和前端验证命令,包括测试、lint、构建检查,以及上传生成 PDF 简历并验证匹配、生成结果和 trace 页面的端到端 smoke flow。
- 在部署设计中考虑 HttpOnly cookie 认证、CSRF 防护、环境变量密钥、CORS 控制,以及未来基于 Postgres pgvector 的向量存储。
挑战
- 在让 AI 求职文案更有说服力的同时,确保内容仍然基于用户真实简历证据。
- 将耗时的 LLM 工作流与普通 API 请求解耦,同时避免产品体验变慢或变得不透明。
- 设计对调试有帮助的 Agent trace 输出,但又不能让用户被内部实现细节淹没。
收获
- 求职类 AI 产品的核心价值不是通用文本生成,而是基于证据重组和转化已有经历。
- 当 LLM 输出会影响求职这种高风险决策时,可观测工作流非常重要。
- 一个偏生产化的 AI 应用从一开始就需要考虑模型编排、队列、认证、测试和部署设计。