Multimodal / LLM App / Full-stack
2026
Role: User scenario definition, multimodal workflow design, recommendation logic design, full-stack MVP implementation
StyleSnap
A multimodal consumer AI product that digitizes wardrobe items from images and recommends daily outfits based on weather, occasion, target style, and user preference.
Impact: Built a complete AI product loop from wardrobe intake to recommendation result, showing how a consumer AI idea can be validated through real interaction, scoring logic, and explainable output.
Overview
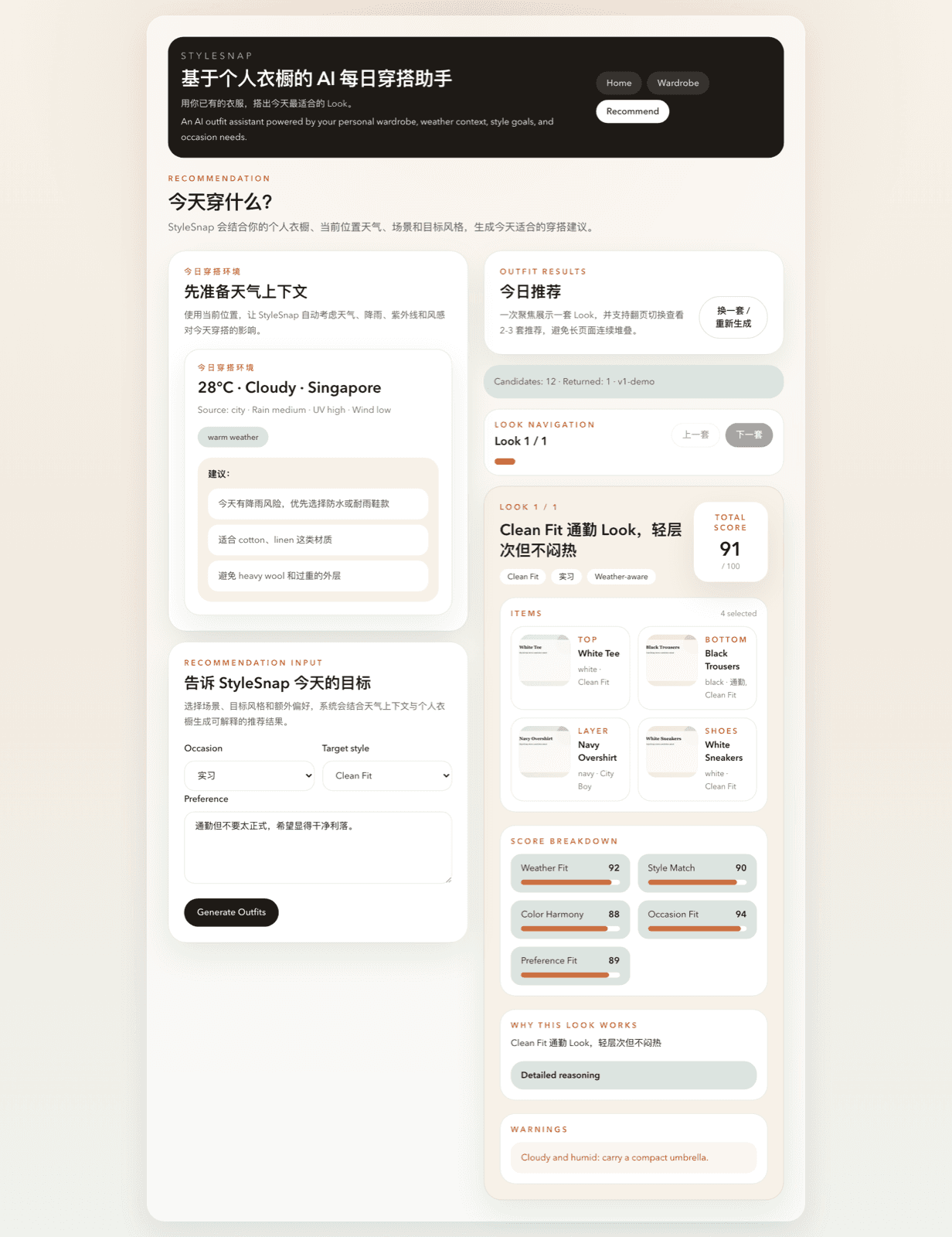
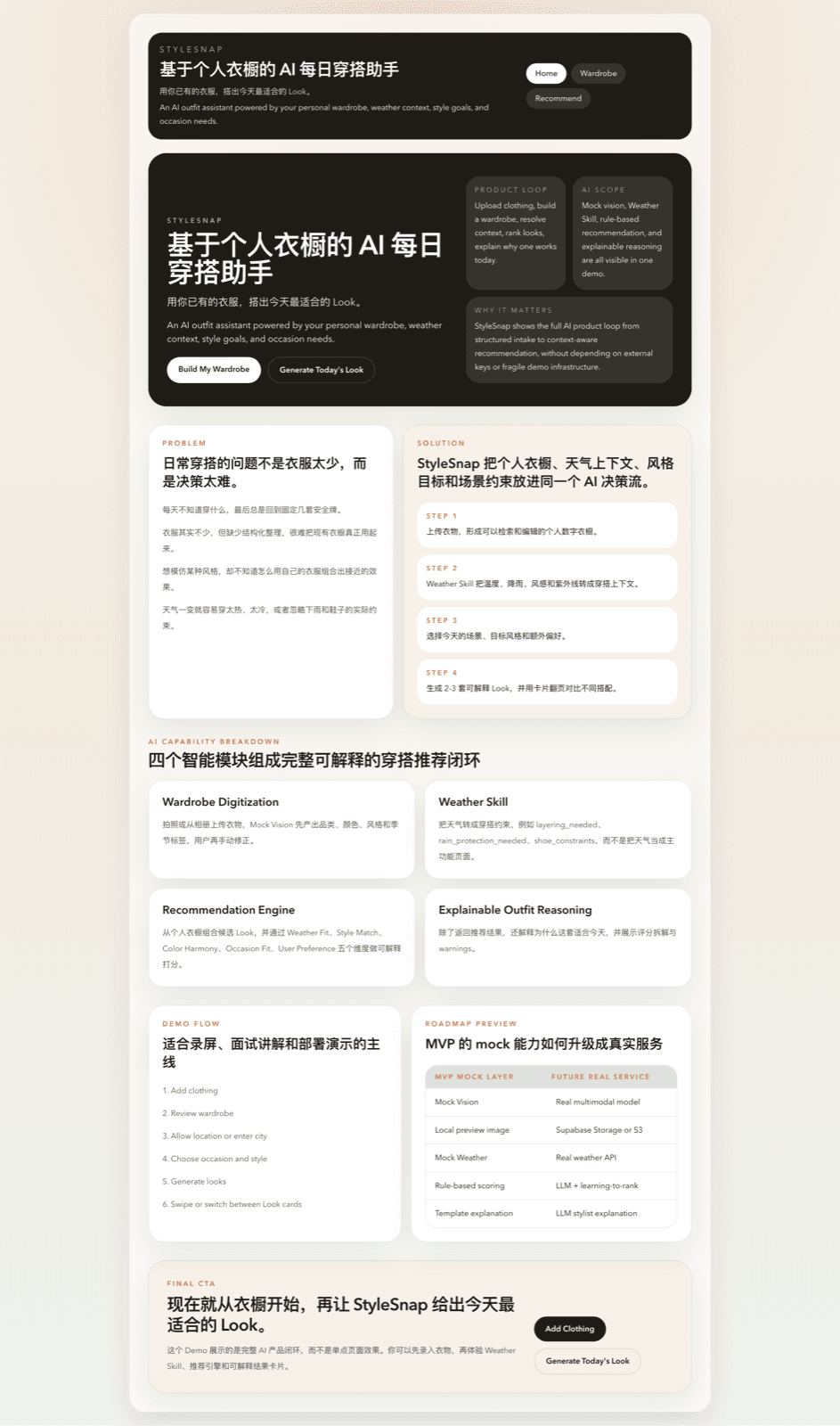
StyleSnap is a multimodal outfit assistant designed as a product loop: users upload clothing images, build a digital wardrobe, provide context like weather and occasion, then receive 2-3 explainable looks grounded in their own closet.
Problem
People often repeat the same safe outfits even when they own many clothes. Target styles are easy to admire online but hard to recreate from an existing wardrobe, and weather affects layering, shoes, comfort, and materials in ways users do not always consider explicitly.
Solution
I defined the wardrobe as the source of truth, then layered weather context, occasion constraints, target style, color harmony, and user preference on top. This lets the system generate recommendations that feel personal, bounded, and reviewable instead of arbitrary.
Architecture
The MVP uses React, Vite, TypeScript, TailwindCSS, and React Router on the frontend, with FastAPI, SQLAlchemy 2, Pydantic, and SQLite on the backend. The backend exposes stable APIs for clothes CRUD, clothing analysis, weather context, and outfit recommendation, while keeping AI vision, weather, scoring, recommendation, and reasoning behind replaceable service boundaries.
Core Features
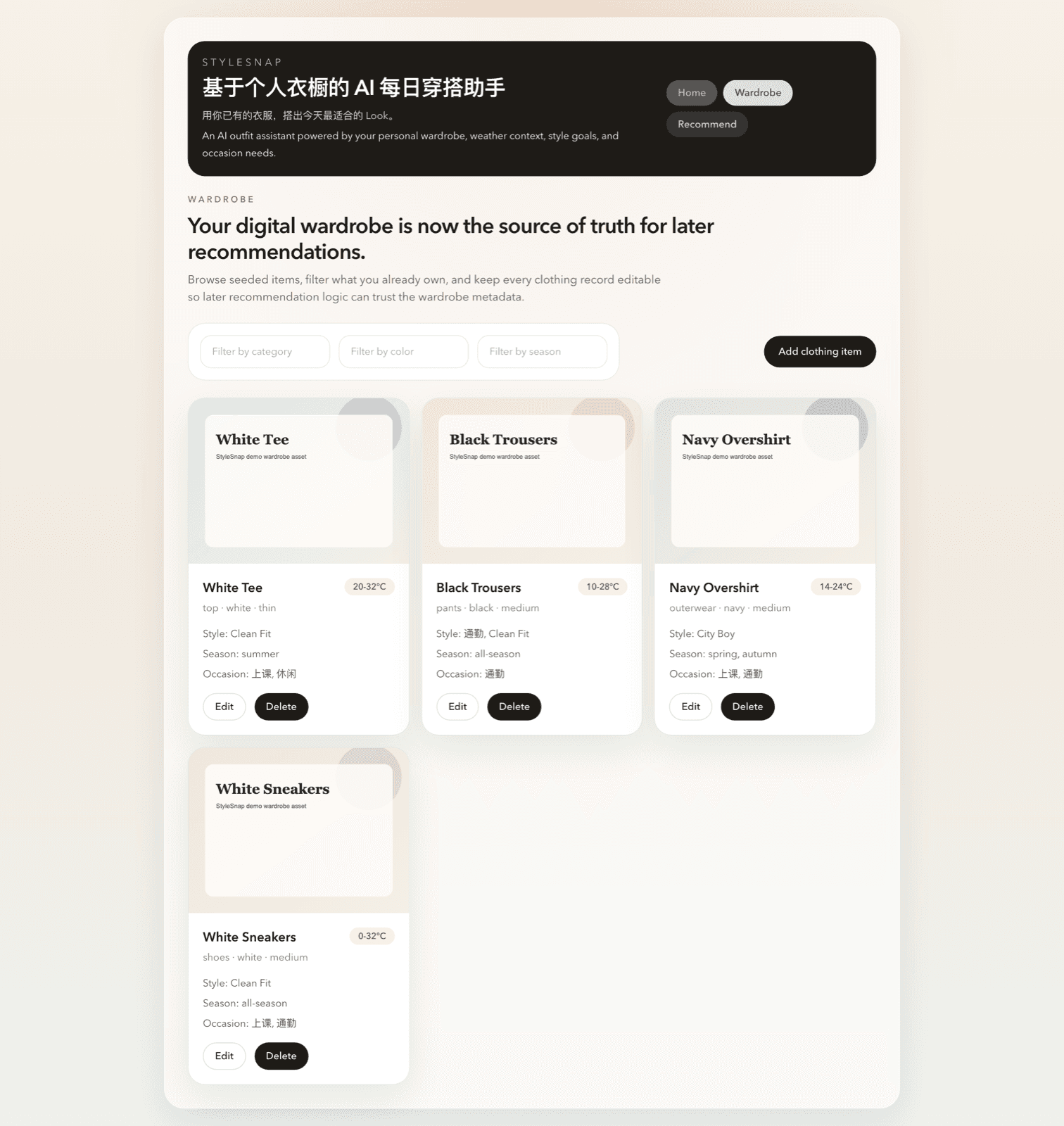
- Upload-first wardrobe intake through camera, album, drag-and-drop, or local image upload
- Editable clothing metadata including category, color, style, season, and occasion tags
- Wardrobe CRUD, filters, and persisted wardrobe-based recommendation
- Weather Skill that converts raw weather into outfit-aware constraints
- Deterministic outfit scoring across weather fit, style match, color harmony, occasion fit, and user preference
- Explainable Look cards with score breakdowns, reasoning, warnings, and previous / next navigation
Tech Stack
- TypeScript
- React
- FastAPI
- SQLite
- DeepSeek API
Implementation Details
- Designed the recommendation score as a weighted formula: weather fit, style match, color harmony, occasion fit, and user preference.
- Separated the system into wardrobe digitization, weather skill, recommendation engine, and explainable outfit reasoning to make each AI capability easier to replace and evaluate.
- Kept rule-based recommendation as the source of truth while using the DeepSeek stylist layer to enhance explanation, improve tone, and optionally reorder already-selected looks.
- Designed fallback-safe provider behavior so failures in the stylist provider or vision provider do not break recommendation or clothing analysis endpoints.
- Added privacy-oriented boundaries: API keys come from environment variables, the backend does not log keys, and the stylist provider receives structured clothing metadata rather than raw images in the current phase.
Challenges
- Balancing deterministic recommendation with LLM-generated styling language so the product remains explainable instead of arbitrary.
- Designing a mock-to-real architecture where vision, weather, storage, and stylist reasoning can be replaced without rewriting the product flow.
- Keeping wardrobe photos useful for AI without turning the MVP into a privacy-risky image storage product too early.
What I Learned
- A strong AI product demo should show a complete loop, not disconnected AI-looking pages.
- For multimodal recommendation products, structured intermediate metadata is more reliable than sending raw observations directly into a language model.
- Explainability matters in subjective domains because users need to compare options, understand tradeoffs, and override the system.